Source repo: sdsc-summer-institute-2022 | Branch:
main| Last synced: 2026-04-24 10:27:17.425 UTC
Data Management: Or how (not) to handle your data in an HPC environment
- Before we begin: A few disclaimers
- Easy access: Setting up SSH keys
- CIFAR through the tubes: Downloading data from the internet
- More files, more problems: Advantages and limitations of different filesystems
- Going parallel: Lustre basics
- Back that data up: Data transfer tools
Before we begin: A few disclaimers
:running: on 🐧
HPC and advanced CI run on Linux. If you don't believe me, then look no further than the latest statistics from the TOP500 --- a list of the most powerful supercomputers in the world. Therefore, in this session we will use --- almost exclusively --- standard command-line tools and applications that are available for Unix-like operating systems such as Linux and macOS. While you will have remote access to a Linux environment on Expanse today via the training account you were provided for the Summer Institute, you will also need access to a *nix environment on your personal computer to complete some of the exercies we'll work through during this session.
Recommendation for Windows users: Install the Windows Subsystem for Linux on your personal computer.
Data has a lifecycle. Data management is a lifestyle.
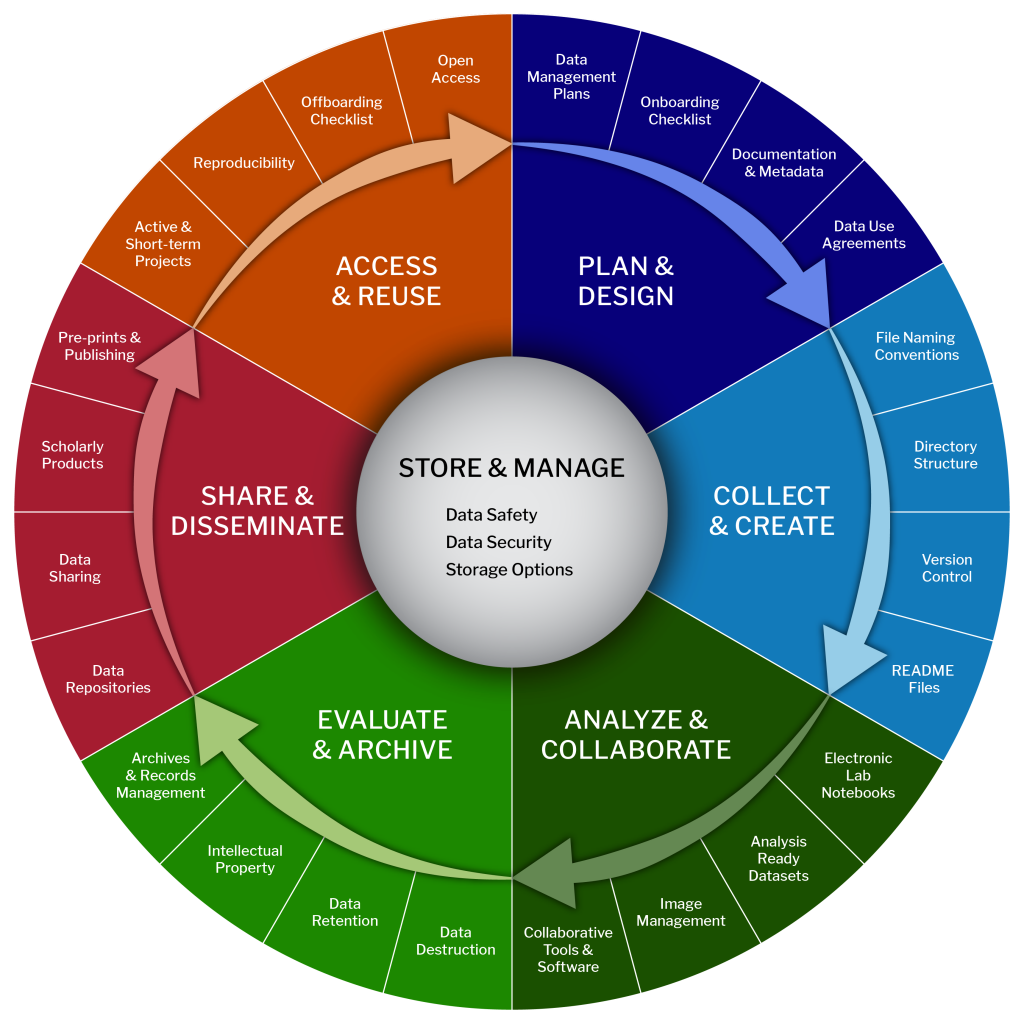
Image Credit: Harvard Biomedical Data Management